AI Inference Server
With Qualcomm NPU.
In a Nutshell.
Capable of Handling Various LLMs
through V-Raptor Q100

The Fastest Arm Processor Ever,
up to 128 Cores

Qualcomm's High-performance,
Low-power Cloud AI NPU
Qualcomm Cloud AI NPU is
More Efficient than GPUs
in Power, Cost & Concurrency.
Qualcomm NPU inference servers, lower initial introduction cost than GPUs,
enable stable service operation with an AI-optimized architecture design.

870 TOPSINT8 Performance at TV-level Power.
Qualcomm Cloud AI 100 Ultra is an energy-efficient AI inference accelerator solution that delivers 288 TFLOPs of FP16 performance and 870 TOPs of INT8 performance at a low power consumption of 150W.
XSLAB has developed servers that achieve outstanding AI inference performance by incorporating this Qualcomm NPU. Combined with Arm-based CPUs for low power and high efficiency, these systems are suitable for a variety of environments, such as modular data centers, on-premise appliances, and edge computing.
Experience the V-Raptor Q100 now—an ultra-efficient AI inference accelerator optimized for data centers and edge environments, seamlessly integrated with low-power, high-performance Arm servers.
Up to 128GB dedicated memory
LPDDR4x Standard with 548GB/s Bandwidth
Through Dedicated Transformer Library
Easy Porting in Optimized Formats
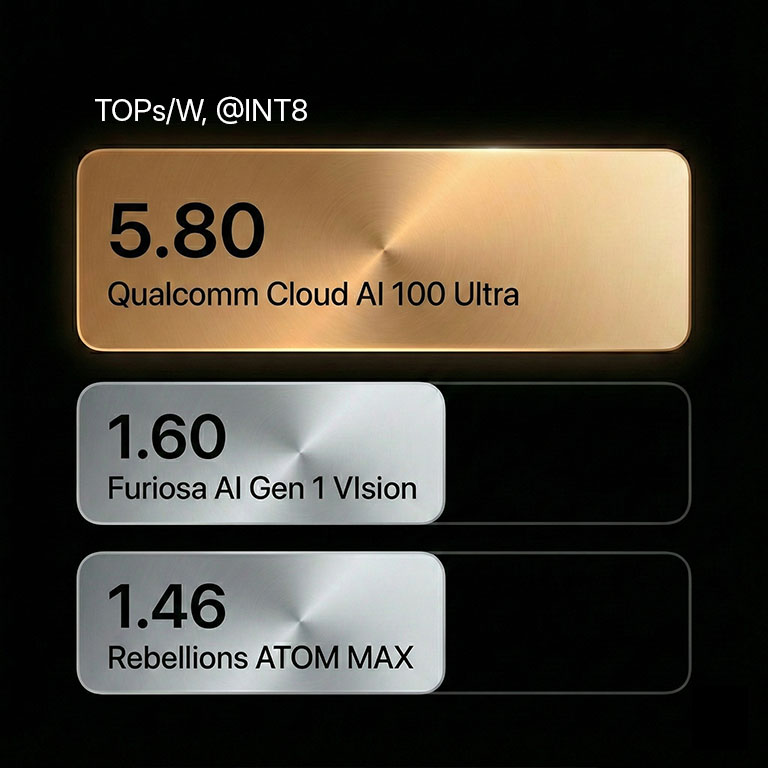
Reduces power costs with unrivaled inference performance per watt. TOPS from each firm's website

The Qualcomm AI Inference Suite enables you to utilize various AI models and services within a GUI environment.

AI NPU built on the proven technological expertise of global semiconductor leader Qualcomm.
And, with Ampere Altra Arm Chip
Works On Everything.
Powered by up to 128 Arm cores running at 3GHz,
the Ampere Altra series is a SOTA chip
designed to handle everything, from server applications
like NGINX and MySQL to cutting-edge multi-modal AI workloads.
Up to 128x Arm v8.2+ Cores
TDP 183W of Low Power drives
Ultra-high Performance Intelligent
200% Increased Bandwidth
Record-high Connection Speeds
with PCIe 4 Support
Up to 4TB Memory
DDR4 3200Mhz
8ch 16 Slots2DPC Support
High-grade Performance
Now in Your Server
V-Raptor Q100 offers flexible core configurations to meet your performance needs. How? With 12 well-defined processor categories — from 32 cores at 1.7GHz to 128 cores at 3.0GHz, and TDP options ranging from 40W to 183W. The choice is yours.
BMC function enables remote access and management of servers using dedicated advanced processors from ASPEED. In other words, you can operate it even if you are far away from the server. It's like carrying the server in your pocket wherever you go.
Inconvenient Truth About GPU Servers?

AI Inference isn't
Something GPUs would do.
While model inference has a lighter computational load than training, using high-performance GPUs causes power consumption and operating costs to swell, leading to a sharp drop in resource efficiency. Consequently, it often becomes an uneconomical choice that results in a high TCO (Total Cost of Ownership) relative to low resource utilization. AI inference is a job for the NPU.

Using GPU servers for AI inference is both costly and excessive.

Relying on GPUs for the inference stage results in a significant waste of power and budget.

In real-world AI deployments, the volume of inference tasks far outweighs that of training.
See Configurations.
Available LLMs
![]()
![]()
![]()
![]()
![]()
In addition, various LLM models are supported.
Provides intuitive and easy-to-use functionality as it is driven by Qualcomm AI Inference Suite
Available Generative AIs
![]()
Retrieval-based Voice Conversion
![]()
Easily use various generative AI such as image generation and audio generation
More power efficient than any other AI workstation
Faster and bottleneck-free computations powered by Arm®-based many-core architecture
Specs
|
Generative AI
|
|
Arm® based Ampere Altra® processor
Up to 128C 3.0Ghz |
|
Qualcomm Cloud AI
NPU Series |
|
DDR4 3200
8ch 2DPC 16 Slots Up to 4TB Memory |
|
M.2 NVMe®
8 Slots |
|
Up to 20x faster transfer
USB 3 supported |
|
10 Gigabit Ethernet
|
|
Ubuntu Server 20.04/22.04 LTS
Rocky Linux 9 |
|
BMC specialised
ASPEED® 2500 |
|
Qualcomm Cloud AI is a product of Qualcomm Technologies, Inc. and/or its subsidiaries.
|
Processor
Ampere Altra® series
Q32-17
32C 1.7Ghz
TDP 40W
Q64-22
64C 2.2Ghz
TDP 124W
Q80-30
80C 3.0Ghz
TDP 161W
M128-30
128C 3.0Ghz
TDP 183W
Arm® v8.2+ & SBSA 4 instruction sets
TSMC 7nm FinFET
1MB L2 cache
Operate from 0°C to 90°C
4,962-pin FCLGA
NPU
Qualcomm® Cloud AI Series
AI 100 Ultra
870 TOPs (INT8)
TDP 150W
128GB RAM
AI 100 Standard
350 TOPs (INT8)
TDP 75W
16GB RAM
AI 080 Ultra
618 TOPs (INT8)
TDP 150W
128GB RAM
AI 080 Standard
190 TOPs (INT8)
TDP 75W
16GB RAM
PCIe FH3/4L or HHHL Size
PCIe 4
7nm