
In a Nutshell.
Capable of Handling Various LLMs
through V-Raptor Altra WS

The Fastest Arm Processor Ever,
up to 128 Cores

High-speed GPU Connectivity
via PCIe 4.0 Support
With Ampere Altra
Arm Chip
Works On Everything.
Powered by up to 128 Arm cores running at 3GHz,
the Ampere Altra series is a SOTA chip
designed to handle everything,
from server applications
like NGINX and MySQL to cutting-edge multi-modal AI workloads.
Up to 128x Arm v8.2+ Cores
TDP 183W of Low Power drives
Ultra-high Performance Intelligent
200% Increased Bandwidth
Record-high Connection Speeds
with PCIe 4 Support
Up to 4TB Memory
DDR4 3200Mhz
8ch 16 Slots2DPC Support
Server-grade Performance
Now in Your Compact Workstation
V-Raptor Altra offers flexible core configurations to meet your performance needs. How? With 12 well-defined processor categories — from 32 cores at 1.7GHz to 128 cores at 3.0GHz, and TDP options ranging from 40W to 183W. The choice is yours.
BMC function enables remote access and management of servers using dedicated advanced processors from ASPEED. In other words, you can operate it even if you are far away from the server. It's like carrying the server in your pocket wherever you go.
Approaching at
Four-times Speed.
Comparison of Intel Xeon Gen 4 and LLaMA 3.2 Prompt Eval
with the same NVIDIA L40S GPU installed.

V-Raptor Altra is a new era of data centre AI servers with a seamless many-core configuration. It is our fastest processor and connectivity combination ever. Powered by the powerful Ampere Altra chip, it can achieve up to 4x faster inference speeds on LLMs such as LLaMA and DeepSeek compared to 4th gen Intel Xeon processors.
Same GPU
4x Faster LLM Inference
Arm AI Workstation
And Ollama allows you to use it more freely, as you can chat with it through the GUI, like using a chat service. You can ask coding questions through text messages, or even ask it to write a poem praising the Arm server.
Nowadays, AI is leading technological innovation and opening a new paradigm. The spread of intelligent technology across industries and daily life is now a universal phenomenon. Accordingly, the use of large language models is rapidly increasing, and they are playing a key role in various industrial fields and rapidly expanding their influence.

LLaMA 3.2 3B
Prompt Eval (Short Question)

DeepSeek R1 7B
Prompt Eval (Short Question)

DeepSeek R1 7B
Prompt Eval (Long Question)
Studio-class Image Generation.

Create
Fun & Beautiful
Image Right for You.
Thanks to NVIDIA CUDA® technology for Arm architecture, image generation AI such as Stable Diffusion can now create the image you want right away. You can use V-Raptor Altra as an image generation workstation for multiple users, the number of concurrent users depending on the GPU configuration.

Low-quality images can be improved through GAN. Let's apply it to a portrait. Done! Just specify the desired variables and it's done.
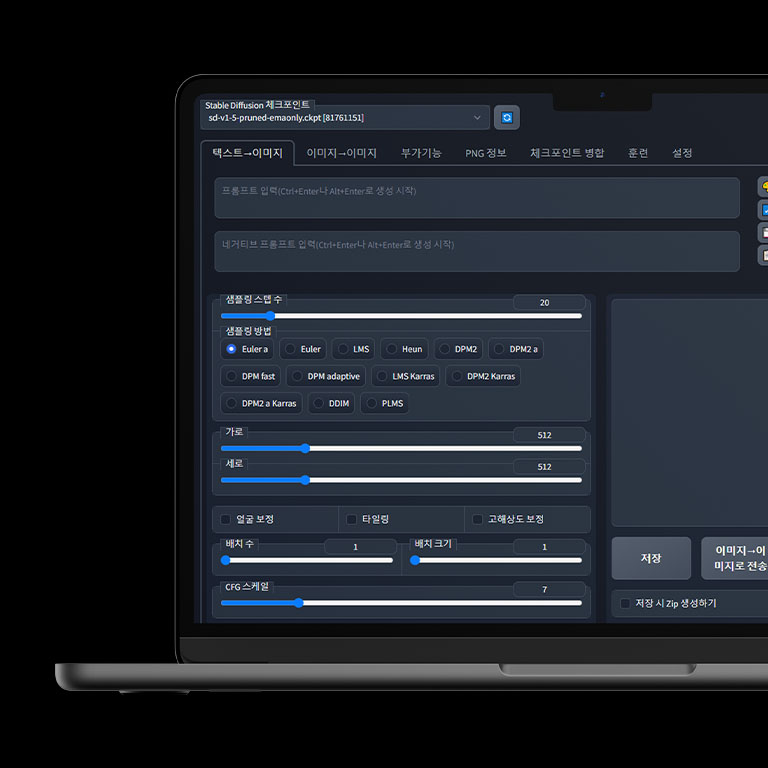
Create new images in seconds from prompts or images via the Web UI. You can also apply various styles such as photos, anime, drawings, etc.

Create infinite combinations of images using the diffusion model of your choice. The parametres of the available models depend on your GPU.
See Configurations.

AI Workstation
with RTX™ 5060Ti
>

AI Workstation
with A40

AI Workstation
with L40S

AI Workstation
with RTX™ PRO 5000
NVIDIA
RTX™ 5060Ti
CUDA® cores
4,068
VRAM
16GB
Architecture
NVIDIA Blackwell
With the latest NVIDIA Blackwell-based 4,608 CUDA® cores and 16GB VRAM, it's perfect for building personal AI or running small models.
NVIDIA
A40
CUDA® cores
10,725
VRAM
48GB
Architecture
NVIDIA Ampere
With the NVIDIA Ampere-based 10,725 CUDA® cores and 48GB VRAM, it's perfect for bbuilding group AI or running large models.
NVIDIA
L40S
CUDA® cores
18,176
VRAM
48GB
Architecture
NVIDIA Ampere
With the NVIDIA Ampere-based 18,176 CUDA® cores and 48GB VRAM, it's perfect for building group AI or running large models.
NVIDIA
RTX™ PRO 5000
CUDA® 코어
14,080
VRAM
48GB
아키텍처
NVIDIA Blackwell
With the latest NVIDIA Blackwell-based 14,080 CUDA® cores and 48GB VRAM, it's perfect for building group AI or running large models.
RTX™ 5060Ti
LLM Concurrent Users (FP16)
LLaMA 3.2 1B
7 people
LLaMA 3.2 3B
2 people
DeepSeek R1 7B
1 people
HYPERCLOVA X SEED 0.5B
14 people
HYPERCLOVA X SEED 1.5B
4 people
Kanana 1.5 2B
3 people
A40
LLM Concurrent Users (FP16)
LLaMA 3.2 1B
23 people
LLaMA 3.2 3B
7 people
LLaMA 3.1 8B
2 people
DeepSeek R1 7B
3 people
HYPERCLOVA X SEED 0.5B
43 people
HYPERCLOVA X SEED 1.5B
15 people
Kanana 1.5 2B
10 people
Kanana 1.5 8B
2 people
L40S
LLM Concurrent Users (FP16)
LLaMA 3.2 1B
23 people
LLaMA 3.2 3B
7 people
LLaMA 3.1 8B
2 people
DeepSeek R1 7B
3 people
HYPERCLOVA X SEED 0.5B
43 people
HYPERCLOVA X SEED 1.5B
15 people
Kanana 1.5 2B
10 people
Kanana 1.5 8B
2 people
RTX™ PRO 5000
LLM Concurrent Users (FP16)
LLaMA 3.2 1B
23 people
LLaMA 3.2 3B
7 people
LLaMA 3.1 8B
2 people
DeepSeek R1 7B
3 people
HYPERCLOVA X SEED 0.5B
43 people
HYPERCLOVA X SEED 1.5B
15 people
Kanana 1.5 2B
10 people
Kanana 1.5 8B
2 people
Available LLMs
![]()
![]()
![]()
![]()
![]()
In addition, various LLM models are supported.
Provides intuitive and easy-to-use functionality as it is driven by a Web UI
Available Generative AIs
![]()
Retrieval-based Voice Conversion
![]()
Easily use various generative AI such as image generation and audio generation
More power efficient than any other AI workstation
Faster and bottleneck-free computations powered by Arm®-based many-core architecture
Specs
|
Generative AI
|
|
Arm® based Ampere Altra® processor
Up to 128C 3.0Ghz |
|
NVIDIA
GPUs |
|
DDR4 3200
8ch 2DPC 16 Slots Up to 4TB Memory |
|
M.2 NVMe®
8 Slots |
|
Up to 20x faster transfer
USB 3 supported |
|
10 Gigabit Ethernet
|
|
Ubuntu Server 20.04/22.04 LTS
Rocky Linux 9 |
|
BMC specialised
ASPEED® 2500 |
Processor
Ampere Altra® series
Q32-17
32C 1.7Ghz
TDP 40W
Q64-22
64C 2.2Ghz
TDP 124W
Q80-30
80C 3.0Ghz
TDP 161W
M128-30
128C 3.0Ghz
TDP 183W
Arm® v8.2+ & SBSA 4 instruction sets
TSMC 7nm FinFET
1MB L2 cache
Operate from 0°C to 90°C
4,962-pin FCLGA